Foundry Local For Android Announcement
Neeraj Poddar, Naman Anand

Microsoft has recently announced the Private Preview launch of Foundry Local for Android, marking a significant step forward for on-device intelligence. This new architecture creates a secure, dedicated, and flexible LLM server application that runs directly on Android devices across a wide variety of open source and custom models. This setup enables multiple applications to utilize a single, locally hosted model, which drastically improves privacy, guarantees consistent performance, and minimizes redundant resource usage. NimbleEdge is pleased to have partnered with Microsoft on this endeavor, leveraging our platform expertise and practical experience from large-scale device deployments.
For several years, NimbleEdge has focused on enabling AI workloads to run directly on user devices with predictable latency and strong privacy. DeliteAI, our on-device AI SDK, has scaled across more than 30 million devices and continues to shape how developers build intelligent experiences locally. Foundry Local for Android aligns closely with this mission. It acts as a foundational layer in the Android ecosystem, while DeliteAI adds the higher-level intelligence, context, and workflow capabilities that modern applications require.
This blog explains the partnership, the architectural value of the new system, and how DeliteAI extends it to support complex on-device reasoning and agentic behavior. It also outlines what this foundation means for a future where billions of devices can run AI privately and efficiently.
NimbleEdge has worked closely with Microsoft to shape the design and implementation of Foundry Local for Android. Our experience deploying on-device models across millions of real consumer devices provided essential insight into how such a system must behave in practice. Throughout the collaboration, we focused on reliability, resource usage patterns, client registration flows, and the performance characteristics required to support more than one application at a time.
This joint work ensures that Foundry Local is not only technically sound but also realistic for production environments. The result is a system designed to function predictably across varied hardware tiers, from high-end phones to mid-range and emerging market devices with tighter constraints.
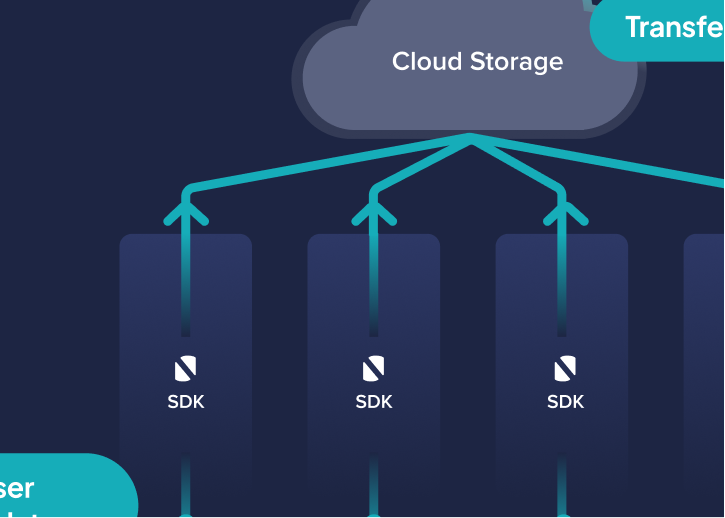
Foundry Local for Android centralizes the model runtime into a single LLM server that any client application can connect to. This avoids the common pattern where each App ships its own runtime and model, often leading to redundant memory use and unpredictable behavior. With a single coordinated server, models are loaded once, kept active in memory, and reused by multiple clients without needing to reload or reinitialize.
This structure also creates a consistent privacy boundary. Since the model operates entirely on the device and is isolated within a managed environment, sensitive data never leaves local storage or memory. Applications can rely on stable latency, predictable performance, and behavior that does not depend on network conditions. Together, these qualities make the architecture more suitable for real-time interactions and multi-step agentic workflows that require uninterrupted execution.
Foundry Local provides the base runtime, while DeliteAI adds the intelligence needed to build real applications on top of it. Through DeliteAI, developers can incorporate context engineering, structured session memory, and in-session reasoning that lets the model keep track of ongoing tasks. This helps applications move beyond simple prompts and toward adaptive interactions that respond to user behavior over time.
DeliteAI also provides a complete tool-calling layer that captures the model’s response, invokes the appropriate functions on the client device, and routes results back into the reasoning loop. This enables agentic workflows such as accessing real-time web based APIs, fetching local preferences, retrieving device information in a controlled manner, or invoking App specific Kotlin methods for custom UI rendering. Because all of these steps occur on the device, the model can perform multi-step tasks without depending on cloud connectivity.
With these capabilities, developers gain a practical path to creating AI-native mobile experiences. They do not need to manage context windows manually, define complex orchestration layers, or build their own reasoning loops in Kotlin. DeliteAI handles these concerns while Foundry Local provides the underlying performance and privacy guarantees.
NimbleEdge and Microsoft share a long-term view of the future of on-device AI. A unified LLM server is the right foundation for scaling intelligence across billions of devices, but the foundation alone is not enough. Continued improvements in model efficiency, scheduling strategies, memory management, and tool-calling depth will expand what developers can build on top of Foundry Local.
NimbleEdge will continue to contribute engineering expertise, provide developer tooling through DeliteAI, and support new workflows that align with agentic mobile applications. As these capabilities mature, on-device AI will shift from being an advanced feature to becoming a standard layer of the mobile stack.

This architecture consists of three core components: the Foundry Local Android Application (FLAA), the Foundry Local Android SDK (FLAS), and the DeliteAI SDK.
FLAS is integrated into the client application. It abstracts all AIDL and IPC complexity, allowing developers to load and interact with on-device models through a simple, high-level API instead of implementing low-level binder communication. This keeps the client code clean, predictable, and easy to maintain.
FLAA runs as the on-device LLM server. It hosts the model runtime, manages the model lifecycle, and handles inference requests that arrive from FLAS instances inside different applications. By centralizing the runtime in a single process, FLAA removes redundant memory usage and provides consistent performance across the device.
DeliteAI acts as the bidirectional intelligence layer between FLAS and FLAA. Every request, whether triggered by the client app or by the LLM server, flows through DeliteAI’s Python-based stream processing engine. This layer maintains structured context, interprets the model’s response, detects when tool calling is needed, and invokes Kotlin functions through a lightweight and efficient JNI bridge. This gives developers a practical and reliable mechanism for multi-step reasoning, session memory, and tool-driven interactions while ensuring that all computation stays on the device.
DeliteAI operates as a dependency of FLAS and remains entirely on the client application side.
Check out how it all works together in this demo video.
To understand how these three components operate together, let’s walk through a typical inference flow.
The client application begins by invoking the OpenAI compatible ChatCompletions API exposed by FLAS and provides the user’s query as input.
val request = ChatCompletionRequest(
ChatMessage.Role.USER, "get OTP for Amazon from SMS"
)
val res = client?.completeChat(request)The DeliteAI SDK intercepts this request before it reaches FLAA. It forwards the input to a specific function inside the Python driver script, where the context for the session begins to accumulate. You can use this hook to provide additional content that you can build with DeliteAI based on the user’s clicks, events and impressions.
def store_user_message(input):
message_history.append({
"content": input,
"role": "user"
})After the Python function returns, the query is passed to FLAA. FLAA feeds the request to the on-device LLM and produces the model output. Before this output is returned to the client application, the DeliteAI SDK intercepts it and examines the response for any tool-calling intent.
def extract_tool_calls(content):
try:
obj = nm.parse_json(content)
args = {}
if "arguments" in obj:
args = obj["arguments"]
return [{"name": obj["name"], "arguments": args}]
except:
return []If a tool call is detected, the corresponding Kotlin function is executed through the JNI bridge. DeliteAI provides a registerTool() API that allows client applications to declare which tools are available for execution during the initialization.
These registrations are stored inside the Python script as callable function pointers. When the model requests a tool, the Python layer invokes the appropriate Kotlin function through this mechanism.
def call_kotlin_function(tool_call_dict):
functionName = tool_call_dict["name"]
args = tool_call_dict["arguments"]
if functionName in kotlin_functions:
func = kotlin_functions[functionName]
return func(args)
else:
print("function not found")Once the tool call is executed, the result is passed back to FLAA along with the accumulated context. The LLM then evaluates the updated state and determines whether another tool call is needed or if it can produce a final response. If another tool call is required, the DeliteAI interception and Kotlin function invocation cycle continues until the model eventually returns a final output instead of another tool request. Only at that point is the completed response delivered back to the client application.
Foundry Local for Android and DeliteAI represent two halves of a shared vision. Foundry Local provides a secure, consistent runtime that anchors the model at the system level. DeliteAI gives developers the richer capabilities required to build experiences around that model: reasoning, context, tool invocation, and multi-step orchestration.
This partnership is an important step toward making AI a native part of the device rather than a remote service. NimbleEdge will continue working alongside Microsoft and the broader developer community to advance this ecosystem and accelerate the shift toward private, responsive, and intelligent experiences that run directly on user devices.
You can sign up for Foundry Local for Android Private Preview here and reach out to team-ai@nimbleedgehq.ai for integrating your applications with Foundry Local and DeliteAI today!

In today’s world, users expect AI assistants that not only understand their needs but also respond with a voice that feels natural, personal, and immediate. At NimbleEdge, we rose to this challenge by building an on-device AI assistant powered by a custom implementation of Kokoro TTS—leveraging our platform’s unique ability to translate rich Python workflows into efficient, cross-platform C++ code.
Mobile apps across verticals today offer a staggering variety of choices - thousands of titles on OTT apps, hundreds of restaurants on food delivery apps, and dozens of hotels on travel booking apps. While this abundance should be a source of great convenience for users, the width of assortments itself is driving significant choice paralysis for users, contributing to low conversion and high customer churn for apps.

Today AI is everywhere - well almost; at least it’s everywhere in conversations but is it making a real-world impact? Impact on everyone’s daily lives? As