How we build our Privacy-First Personal AI Assistant that lives Entirely on your Phone
Naman Anand

The demand for AI experiences that are fast, private and always available is growing rapidly. According to Clem Delangue, CEO - Hugging Face, there’s a new model, dataset, or app that is built on Hugging Face every 10 seconds. At the heart of this shift is the privacy-first AI assistant - a digital companion that runs entirely on your smartphone, with no cloud fallback, no external data processing and zero latency due to server calls.
In this blog, we’re pulling back the curtain on how we built our on-device AI assistant. Whether you’re building for Android or iOS, consider this your blueprint for bringing intelligent, private AI directly on the edge.
Consumers are increasingly skeptical about how their data is used. A 2023 Cisco study [1] revealed that 81% of users are concerned about AI’s potential to compromise their privacy. When it comes to virtual assistants, always-listening models like Alexa or Siri still rely heavily on cloud connectivity for processing natural language and intent recognition. This creates multiple points of vulnerability, from data-in-transit to server-side breaches.
By shifting the AI assistant entirely to the device, developers gain:
Let’s break down the core components we’ve used to build a full-featured on-device AI assistant:
At the heart of our on-device AI platform is a thoughtfully engineered, fully abstracted SDK designed to integrate seamlessly into any mobile app, whether Android or iOS. It empowers developers to load and run a wide range of ML models from lightweight recommendation engines to full-fledged LLMs entirely on-device. Optimized for performance across the device spectrum, from low-end phones to flagship hardware.
Our SDK sits atop ONNX, ExecuTorch, and Core ML, giving developers the flexibility to choose the most efficient runtime for their specific use case.
To effectively manage and dynamically switch between different LLMs at runtime, we use a smart router powered by our on-device AI SDK. User intents are captured via Kotlin or Swift, while preprocessing, inference, and post-processing happen entirely on-device through a workflow script written in Python, executed at runtime by our on-device SDK, ensuring data privacy and security.
Real-time, accurate transcription is critical. For this, we integrate:
All preprocessing including audio chunking and noise reduction is performed locally through the same workflow script. The processed transcription is then seamlessly forwarded to the LLM for inference.
The LLM-generated text output undergoes extensive preprocessing including text chunking for improved performance, phonemization, and optimization before being sent to the Kokoro model via the workflow script. The resulting PCM audio is seamlessly streamed through Android’s MediaPlayer, providing smooth audio playback to the user.
Curious how we made Kokoro TTS run on-device? Read the full deep-dive here.
We thrive on solving challenging problems, and we’ve identified a significant one in the AI ecosystem today: the lack of discoverability and reusability of AI components across applications.
Imagine you find an AI app with outstanding TTS capabilities but you only need its TTS feature. Currently, you’d have no choice but to source an unpolished TTS model and rewrite all the preprocessing and post-processing logic yourself. This is about to change.
With nimbleSDK, you can run anything from compact recommendation agents to robust LLMs. Building upon the on-device SDK, we’re developing specialized agents that encapsulate key functionalities:
Imagine you’re a developer browsing our marketplace, and you discover an agent that summarizes your notifications before you wake up, automatically playing the summary at your chosen time.
Just add a simple Maven dependency to your app, and instantly integrate powerful AI capabilities—no heavy lifting, no complex configurations.
We’re currently focused on creating foundational, highly-functional AI agents:
Note: While the references in this document reference Android/Kotlin for clarity, our on-device SDK and agents that will be published in the marketplace are fully cross-platform. All functionalities described are equally applicable to iOS/Swift, ensuring seamless integration across both platforms.
Building a privacy-first AI assistant that lives entirely on your phone is no longer aspirational, it’s essential. With the right models, efficient tooling, and mobile-first engineering, it’s possible to ship fast, responsive, and fully private assistants that never leave the user’s device.
At NimbleEdge, we’re building infrastructure to make this journey seamless - empowering developers with SDKs, optimized runtimes, and deployment tools to scale on-device AI assistants that respect user privacy from day one.
Want to join the on-device AI revolution?
Get in touch with our team or explore our NimbleEdge AI Assistant App here.
You can also join our Discord community for the latest updates here.
Sources:
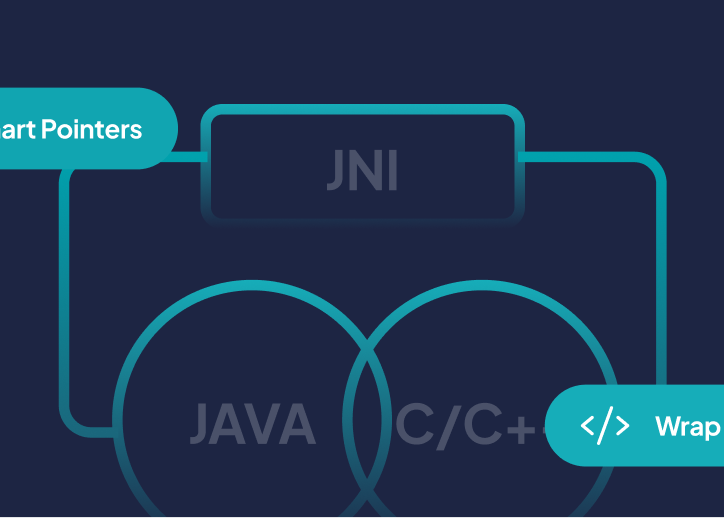
Ever felt Ever felt like JNI was more of a puzzle box than a useful tool? Fear not—today we’re diving deep into JNI without the headaches! 🚀

In our previous blog, we covered how NimbleEdge helps capture event streams

It is a valid question (isn’t it?) that why should we put effort into reducing the size of an SDK, with mobile storage capacities increasing all the time. Surely, how much do a few MBs matter when the device has multiple hundred gigabytes of sto