How to run Kokoro TTS model on-device
Varun Khare

In today’s world, users expect AI assistants that not only understand their needs but also respond with a voice that feels natural, personal, and immediate. At NimbleEdge, we rose to this challenge by building an on-device AI assistant powered by a custom implementation of Kokoro TTS—leveraging our platform’s unique ability to translate rich Python workflows into efficient, cross-platform C++ code.
The result?
An assistant that speaks fluently, responds instantly, and preserves user privacy by running entirely on-device.
We are also open sourcing our implementation of the tokenizer and batch support for Kokoro at Nimbleedge/kokoro
The holy grail for human-like emotional voice generation is being pursued on two fronts today.
Kokoro models (~82M params) come right at the sweet spot. Performing well on TTS leaderboard and fit under 80Mb in size after quantization. We chose the int8 dynamic quantized model with fp16 activations as our primary voice generation model for the AI Assistant.
For the AI to hold a flowing conversation with the user, it needs to support streaming responses for ASR, LLM and TTS. So we designed our workflow as follows
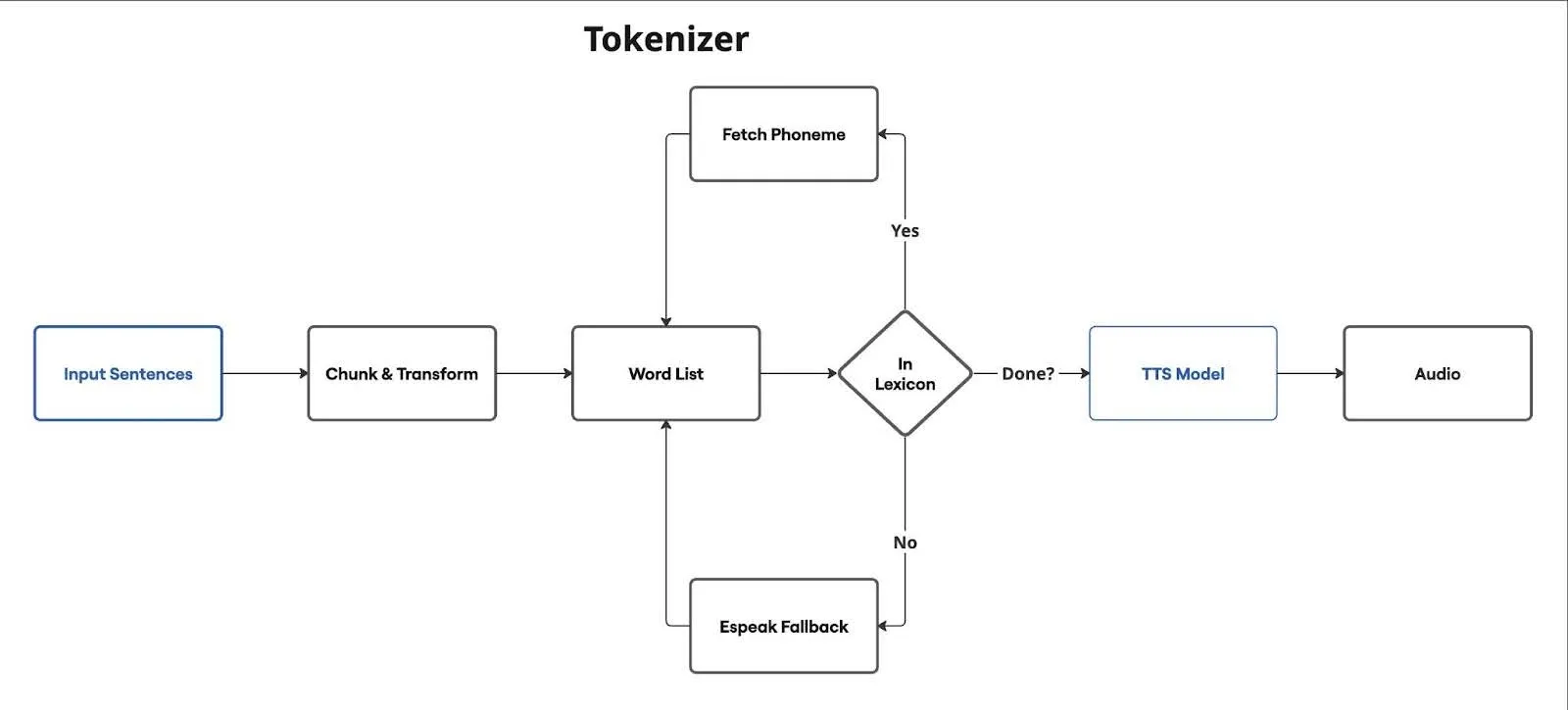
Audio Generation Workflow
A robust tokenizer is the backbone of any high-quality TTS system. Tokenizers break the input sentences to words/tokens and then generate phoneme pronunciation for the TTS model. The author of Kokoro says a good tokenizer raises audio quality while reducing model sizes:

Kokoro’s tokenizer, Misaki (based on G2P) leverages libraries like Numpy, NLTK and Spacy which are not compatible with on-device execution, so we leveraged NimbleEdge’s Python workflow engine to re-implement Misaki for on-device deployment:
Our preprocessing handles edge cases gracefully:
By using NimbleEdge’s Regex library—which compiles Python re patterns into efficient C++ std::regex—we achieve near-native performance for all these operations.
for m in re.finditer(LINK_REGEX, text):
result = result + text[last_end:m.start()]
tokens = tokens + split(text[last_end:m.start()], r' ', False)
original = m.group(1)
replacement = m.group(2)
# Check if this is from regex replacements like [$123.45](123 dollars and 45 cents)
# or explicit like [Kokoro](/kˈOkəɹO/)
is_alias = False
f = ""
@concurrent
def is_signed(s):
if s[0] == '-' or s[0] == '+':
return bool(re.match(r'^[0-9]+$', s[1:]))
return bool(re.match(r'^[0-9]+$', s))
if replacement[0] == '/' and replacement[-1] == '/':
# This is a phoneme specification
f = replacement
elif original[0] == '$' or ':' in original or '.' in original:
# This is likely from flip_money, split_num, or point_num
f = replacement
is_alias = True
elif is_signed(replacement):
f = int(replacement)
nonStringFeatureIndexList.append(str(len(tokens)))
elif replacement == '0.5' or replacement == '+0.5':
f = 0.5
nonStringFeatureIndexList.append(str(len(tokens)))
elif replacement == '-0.5':
f = -0.5
nonStringFeatureIndexList.append(str(len(tokens)))
elif len(replacement) > 1 and replacement[0] == '#' and replacement[-1] == '#':
f = replacement[0] + replacement[1:].rstrip('#')
else:
# Default case - treat as alias
f = replacement
is_alias = True
if f is not None:
# For aliases/replacements, store with 'alias:' prefix to distinguish
feature_key = str(len(tokens))
print("alias: ", f, feature_key, features)
if is_alias:
features[feature_key] = "["+f+"]"
else:
features[feature_key] = fAfter preprocessing, we tokenize sentences into words and then phonemes, following a hierarchical lookup strategy:
if feature is not None and feature[0] == '[' and feature[-1] == ']':
# This is an alias from formatted replacements - remove brackets
alias = feature[1:-1]
phoneme_text = alias
word = split(phoneme_text, r' ', False)
word_punct_split = []
for tok in word:
split_tok = split_puncts(tok)
word_punct_split = word_punct_split + split_tok
word_tokens = []
for idx, tok in enumerate(word_punct_split):
# Generate phonemes using espeak or lexicon
phoneme = ""
whitespace = True
if tok in PUNCTS:
phoneme = tok
whitespace=False
elif LEXICON is not None and tok in LEXICON:
print("found tok", tok, LEXICON[tok])
phoneme = LEXICON[tok]
else:
tok_lower = tok.lower()
if LEXICON is not None and tok_lower in LEXICON:
print("found tok", tok_lower, LEXICON[tok_lower])
phoneme = LEXICON[tok_lower]
else:
print("not found tok lower:"+ tok_lower+ "tok:"+tok)
phoneme = nm.convertTextToPhonemes(tok_lower)
stress = None
if feature is not None and not i in nonStringFeatureIndexList:
stress = featureIntegration of Kokoro ONNX model into the mobile app is just a few simple NimbleEdge platform APIs taking phoneme output from our tokenizer.
kokoro_model = nm.Model("kokoro_")
phonemes = phonemize(input["text"])["ps"]
input_ids = nm.tensor([[0] + tokens + [0]], "int64")
speed = nm.tensor([1.0], "float")
audio = kokoro_model.run(input_ids, speed)However, the generation times were still slow with limited parallelization on android/iOS devices. While LLM generation was running ahead, a single 10 second snippet of generation took about 8 seconds on recent smartphones. This hindered uninterrupted flowing conversation with LLM.
Since tone/prosody variations across sentences are less jerky, we can parallelize across sentences. But wait…
def forward_with_tokens(
self,
input_ids: torch.LongTensor,
speed: float,
input_lengths: Optional[torch.LongTensor]
) -> tuple[torch.FloatTensor, torch.LongTensor]:We update the forward_with_tokens method of KModel class in Kokoro with:
Alignment matrices basically tell us which frames correspond to which tokens in the input sequence. In the current implementation, the model’s duration_proj predicts the number of frames that are allocated to the word.
[[1,1,1,0,0], # -> 101
[1,1,1,1,1], # -> 150
[1,0,0,0,0]] # -> 157Unfortunately, Kokoro uses torch.interleave to construct the alignment matrix which does not work well with batched inputs. So we replace it with mask based computation. This ensures the model could be exported into a static compute graph without expensive loop unrolling gaining speed ups from vectorised operations.
frame_indices = torch.arange(max_frames, device=self.device).view(1,1,-1)
duration_cumsum = duration.cumsum(dim=1).unsqueeze(-1)
mask1 = duration_cumsum > frame_indices
mask2 = frame_indices >= torch.cat([torch.zeros(duration.shape[0],1, 1),
duration_cumsum[:,:-1,:]],dim=1)
pred_aln_trg = (mask1 & mask2).float().transpose(1, 2) # batch,frames,seq_lenONNX export requires removing torch.rand and uniform from voice upsampling as they are not supported for dynamic quantization. We swap the random noise to dynamic compiled noise vector with
noise_amp = uv * self.noise_std + (1 - uv) * self.sine_amp / 3
noise = noise_amp * torch.linspace(0.1, 0.9,
sine_waves.shape[-1]).expand_as(sine_waves)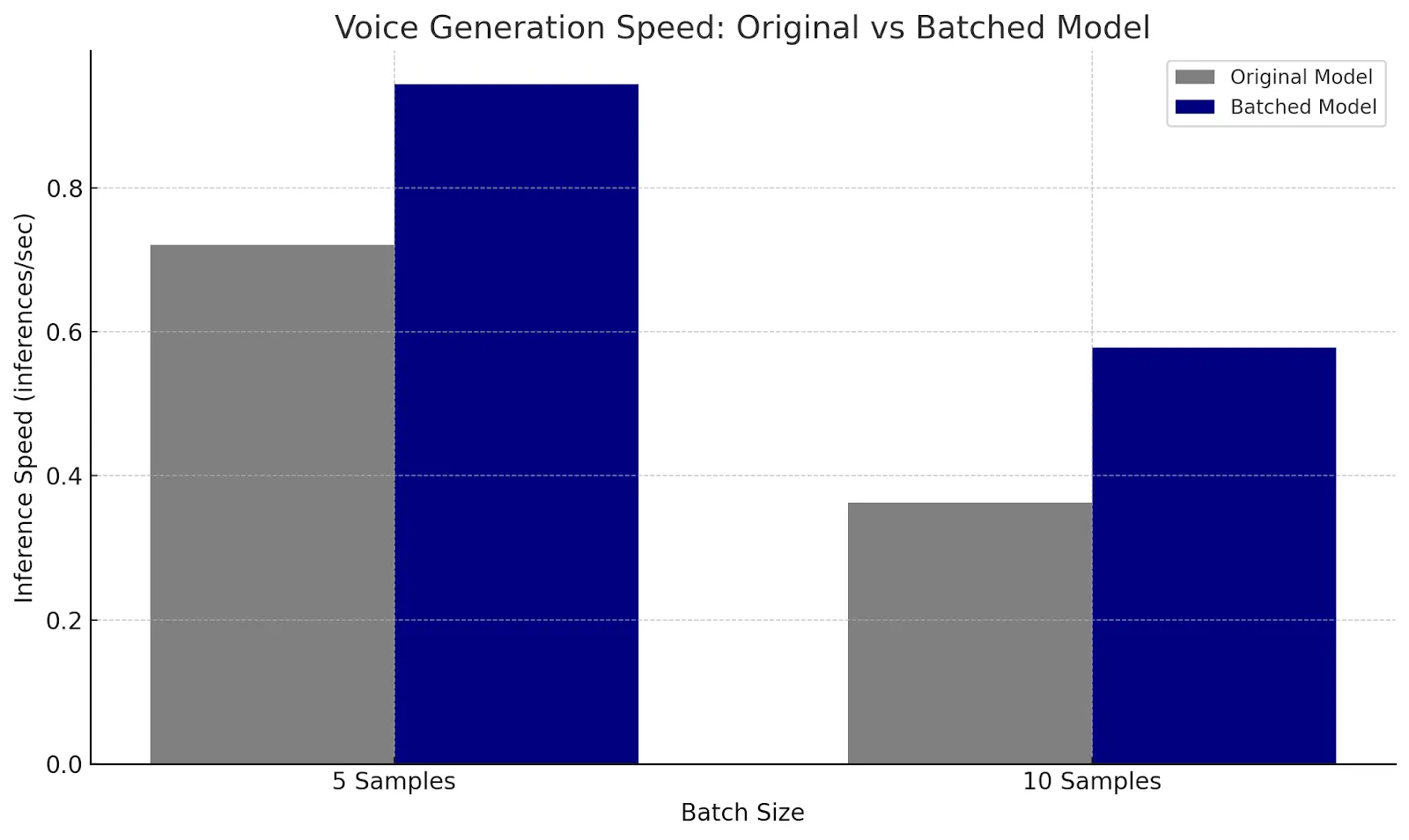
| Time for 1 inference
Batch Size 5 |
Time for 1 inference
Batch Size 10 |
|
| Original model (Sequential) | 1.3888 sec | 2.7557 sec |
| Batched model
(Parallel) |
1.0600 sec | 1.7306 sec |
| Speedup | 1.31x | 1.59x |
*Sequence length = 32
We also evaluated how batching performs under various multi-threading conditions and saw higher speed ups with more parallel cores available validating the bottleneck on parallelization.
Incorporating these techniques, we’re proud to deliver an assistant that provides the experience users truly desire—private, intelligent, open source and always accessible
Explore the future of personalized AI interactions today with our on-device AI Assistant—built for you, and your privacy, at every step.

In our previous blog, we covered how NimbleEdge helps capture event streams
On-Device AI: Why It’s Both the Biggest Challenge and the Ultimate Solution for the Future of Computing

The New Stack: Rethinking AI for Mobile